对EDF/BDF格式的几点想法
如果你在脑电(EEG)或者睡眠监测(PSG)领域工作,大概率听过 EDF 格式,也可能听说过它的升级版 EDF+ 或 BDF。这些格式在科研里用得非常广泛,是研究人员存储和分享数据的“通用语言”。
我之前写过一个 EDF 与其他格式互转的工具(https://github.com/eegdb/eeg_convert),但今天我不打算讲怎么用 EDF,而是想聊聊一个问题:在现代 EEG 设备里,EDF/BDF 还能跟上高采样、多导联和实时性需求吗?
EDF资料
https://www.edfplus.info/specs/edf.html
实时写入
EDF最初是为数据共享和存储设计的,它的核心思想很简单:把数据分块存储,每块叫做一个 record。每个 record 的时长固定,由 8 个 ASCII 字节表示。这样做的好处是结构清晰、解析方便,但对实时写入来说就有些力不从心了。 现在很多 EEG 设备都用无线传输,这就带来两个问题:
-
数据顺序:无线可能乱序,蓝牙\TCP等协议也有重传机制。
-
数据传输过程中意外丢失。
所以,想实时把 EEG 数据写进 EDF,就必须额外维护缓存(buffer),处理这些异常情况。
多模态、多导联的支持
EDF 对多导联、多模态信号的支持有限。举个例子:
假设系统里有两个采集芯片:
-
芯片 A:25 Hz
-
芯片 B:250 Hz
如果要把它们写进同一个 EDF 文件,就要面对 record 时长选择的问题:
-
record 太短 → 分块太多,性能差
-
record 太长 → 单块数据太大,也影响性能
简单分析一下采样周期:
-
25 Hz → 每个采样 0.04 s
-
250 Hz → 每个采样 0.004 s
公共采样周期 → 0.04 s
也就是说,最小 record 时长就是 0.04 s,否则 EDF 结构不允许。另一种方法是写两个 EDF 文件,现实中有人使用多个EDF来记录一个数据么?我不清楚。
时间:
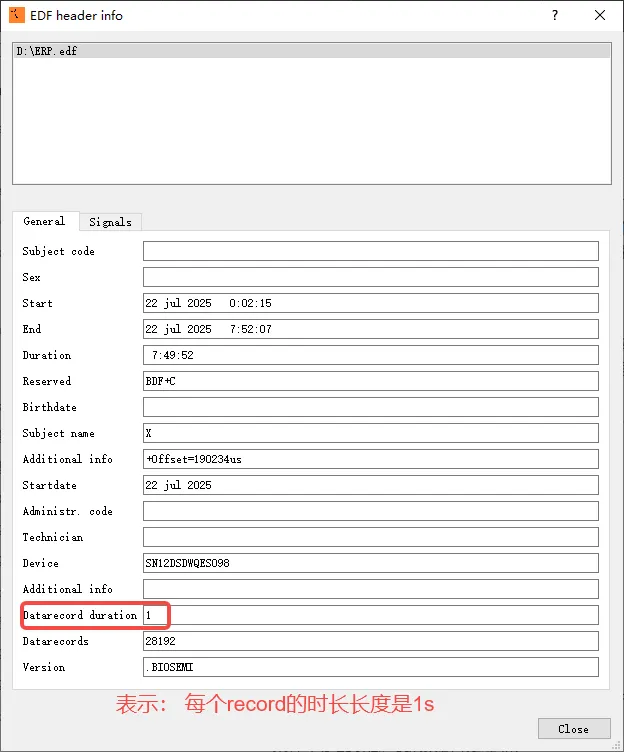
EDF 的时间概念很粗糙:Header 里有开始时间,但精度只到秒。
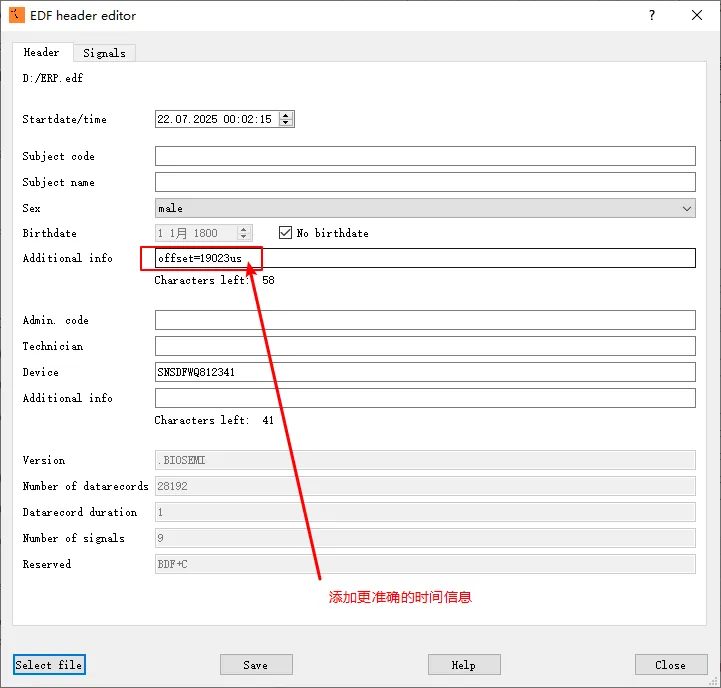
在一些 ERP 或事件相关实验中,秒级精度显然不够。工程上通常会在 EDF 文件里额外加字段来记录更精确的时间:
查询
-
连续数据:可以直接按文件偏移跳到对应时间位置。
-
不连续数据:非连续数据的查询及其糟糕。只能在每一个record里记录相对开始时间的offset。时间查询时可能需要先把所有 record 的 offset 载入内存,再开始查询,也就是说我们需要把整个EDF文件都读一遍。
对于不连续的数据,为了加速查询,我们需要额外建立一个索引表。